반복게임
지금까지의 분석은 one-shot, 즉 1회 게임
현실 세계에서는 동일한 사람들간의 반복적인 상호작용 발생
반복게임의 필요 요소
지금 당장의 보수와 미래의 보수를 비교
반복게임 전략 비교
반복게임의 요소
핵심만 쏙쏙!
다음 문제에 답을 할 수 있다.
현실 세계의 전략적 상황 \(\rightarrow\) 반복적 상호작용 \(\rightarrow\) 반복게임
합리적 경기자들은 반복되는 상황에서 어떤 전략을 선택하는가?
다음 문제를 생각하자.
게임을 반복할 때 과거 어떤 선택을 했는지 알아야 한다.
게임의 역사와 그에 따른 전략을 고려한다.
반복게임
동일한 단계 게임(Stage game)이 유한번 또는 무한번 반복되는 게임
반복게임은 특수한 형태의 전개형게임
반복게임의 균형
내쉬균형과 하위게임완전균형의 개념이 그대로 적용
처음이건 중간이건 누구도 균형전략에서 이탈하더라도 그 이후의 경로가 모든 경기자들에게 원래대로 지켜질 유인 존재
반복게임의 전략
발생가능한 모든 상황에 있어서 경기자가 취할 행동의 완전한 계획
각 경기자의 전략은 1기에 어떠한 행동을 취할 것인가에 대한 계획 포함
1기에 실현된 결과에 대하여 2기에 어떤 행동으로 대응할 것인가 포함
(반복게임) 지나간 과거에 경기자들이 어떠한 선택을 했는지가 중요
반복게임에서의 전략이란 과거 선택한 행동들에 대응하여 수립된 현재의 행동 계획
역사(history)란 무엇인가?
역사(history)
반복게임에서 \(t\)기의 역사(history at period \(t\)}란 1기로부터 \((t-1)\)기까지 경기자들이 선택한 행동들의 기록이다.
\(t\)기에 있어서 역사를 \(h^{t}\)라 표기하면, \(h^{t}=(a^{1},~a^{2},~a^{3},\cdots,~a^{t-1})\)이다.
전략 (strategy)이란 무엇인가?
전략(strategy)
반복게임에서 전략이란 1기에 선택하고자 계획된 행동 및 2기 이후에 그 이전의 역사에 대응하여 계획된 행동이다.
경기자 \(i\)의 \(t\)기 전략 \(s_{it}(h^{t})\)는 주어진 \(t\)기의 역사 \(h^{t}\)하에서 경기자 \(i\)가 \(t\)기에 취할 행동을 지정해 주는 함수이다.
1회 게임(one-shot game)
Player 1의 행동은 \(\{Up,~Down\}\), Player 2의 행동은 \(\{Left,~Right\}\)
유일한 내쉬균형
내쉬균형은 순수전략 내쉬균형으로 \((Down,~Left)\)
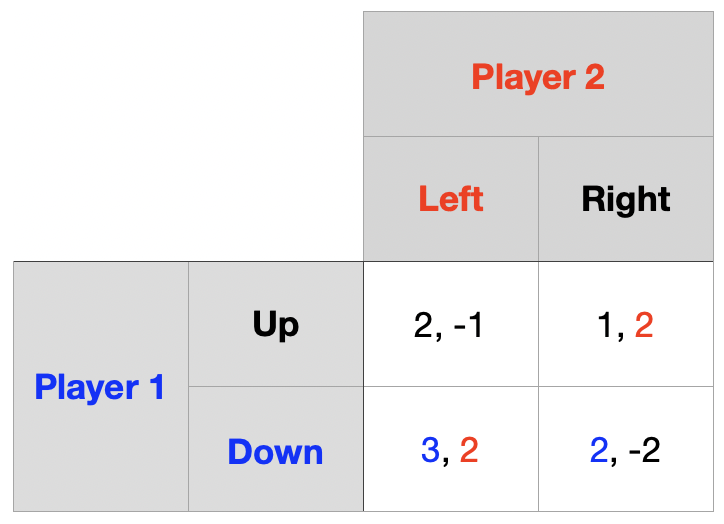
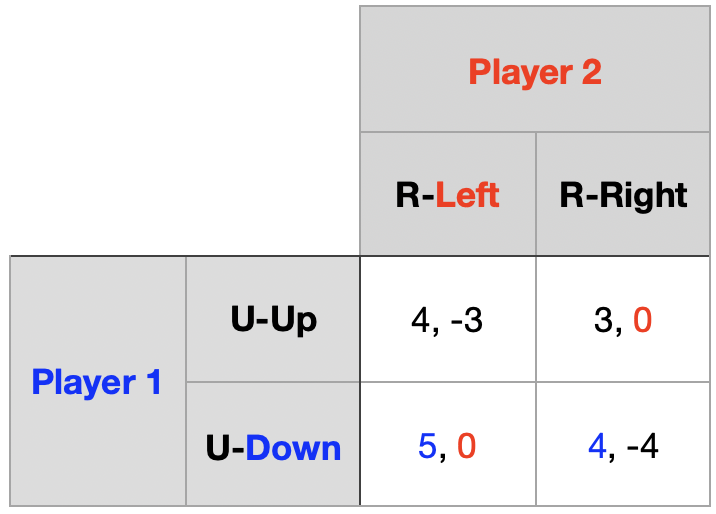
동일한 게임을 2회 유한 반복
Player 1의 행동은 \(\{Up,~Down\}\), Player 2의 행동은 \(\{Left,~Right\}\)
1기 단계 게임의 역사 \((Up,~Right)\) \(\rightarrow\) 보수 \((1,~2)\)
2기 단계 게임의 내쉬균형은 순수전략 내쉬균형으로 \((Down,~Left)\)
1기 단계 게임이 균형에서 이탈하더라도 2기 단계 게임에서는 균형으로 회귀
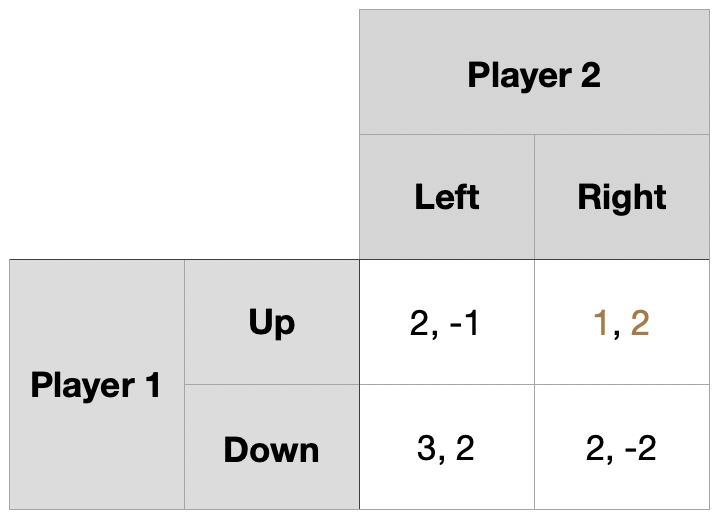
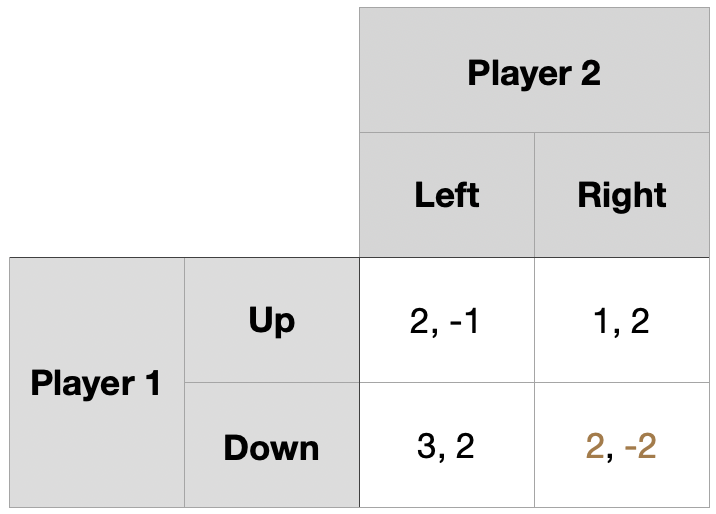
1기 단계 게임 역사 \((Down,~Right)\) \(\rightarrow\) 보수 \((2,~-2)\)
2기 단계 게임의 내쉬균형은 순수전략 내쉬균형으로 \((Down,~Left)\)
1기 단계 게임이 균형에서 이탈하더라도 2기 단계 게임에서는 균형으로 회귀
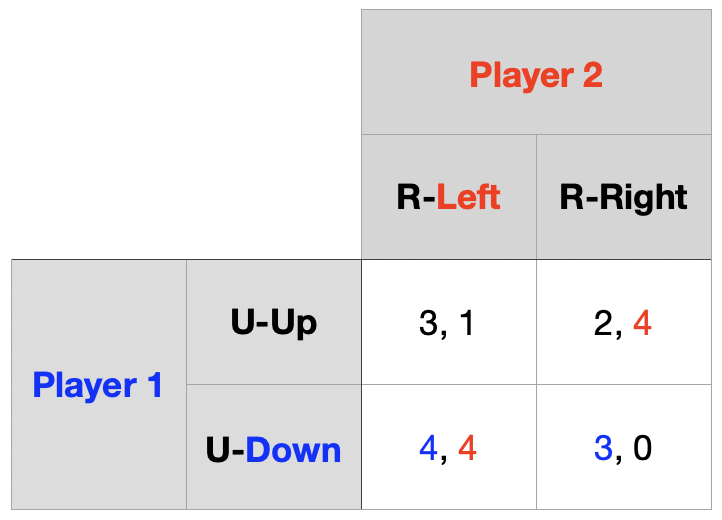
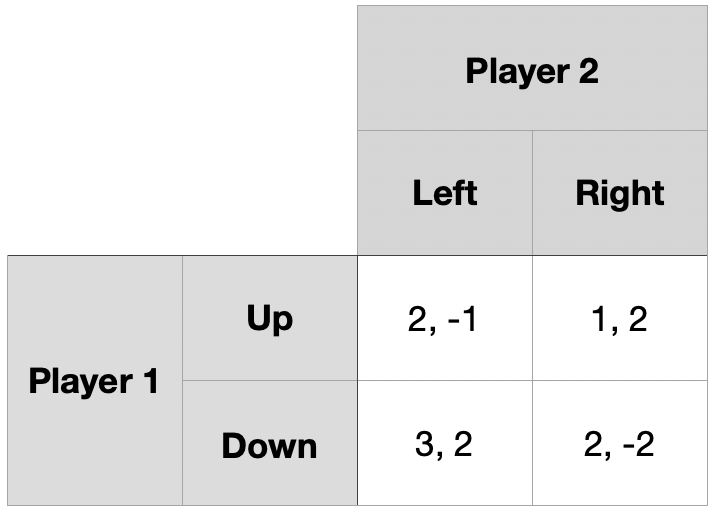
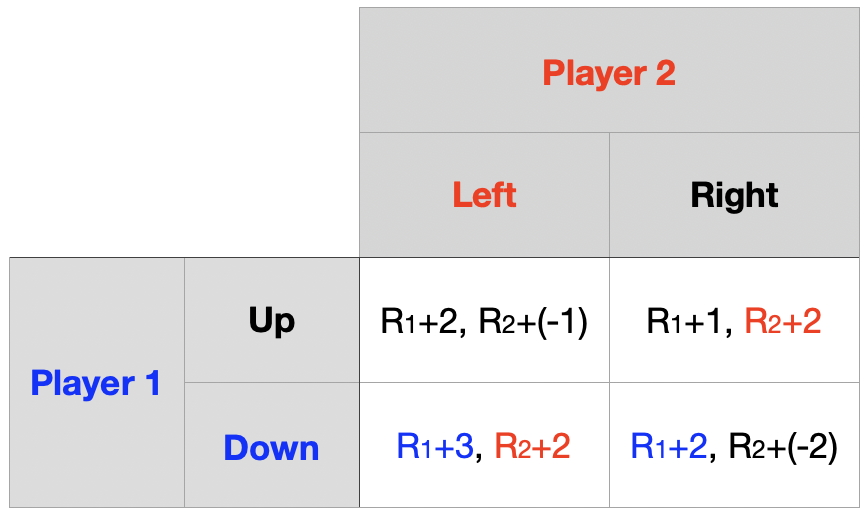
동일한 게임을 \(T\)회 유한 반복
Player 1의 행동은 \(\{Up,~Down\}\), Player 2의 행동은 \(\{Left,~Right\}\)
\((T-1)\)기까지의 정보 $\rightarrow$ \(T\)기의 역사 \(h^{T}\) $\rightarrow$ 보수 \((R_{1},~R_{2})\)
\(T\)기 단계 게임의 내쉬균형은 순수전략 내쉬균형으로 \((Down,~Left)\)
하위게임완전균형을 적용하면 모든 기의 순수전략 내쉬균형은 \((Down,~Left)\)
응용해 봅시다.
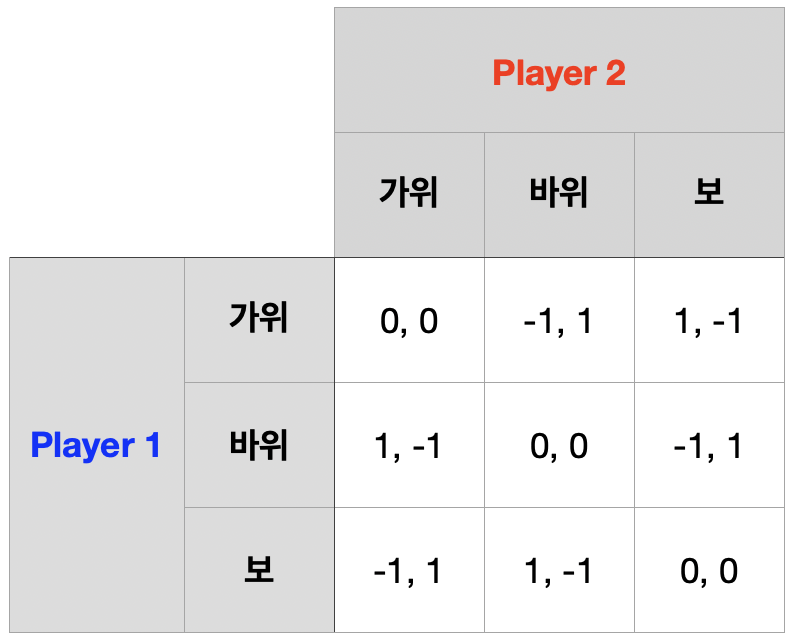
가위-바위-보 게임의 2회 반복
1기 단계 게임의 순수전략 내쉬균형은 존재하지 않는다.
내쉬균형은 혼합전략 내쉬균형으로 순수혼합전략 내쉬균형이다.
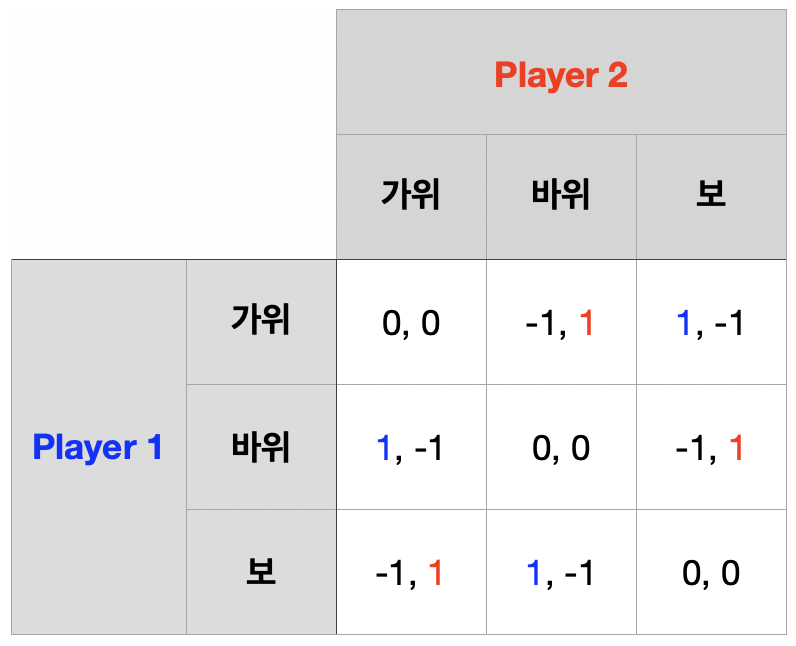
1기 단계 게임의 역사는 각 경기자의 비균형 전략 (바위, 가위)
2기 단계 게임 내쉬균형은 혼합전략 내쉬균형으로 순수혼합전략 내쉬균형이다.
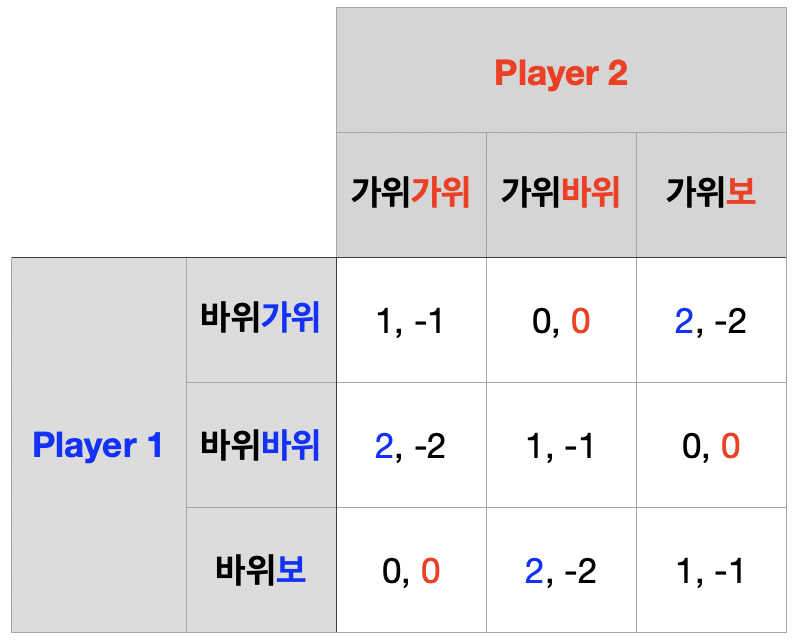
1기 단계 게임의 역사는 각 경기자의 비균형 전략 (가위, 바위)
2기 단계 게임 내쉬균형은 혼합전략 내쉬균형으로 순수혼합전략 내쉬균형이다.
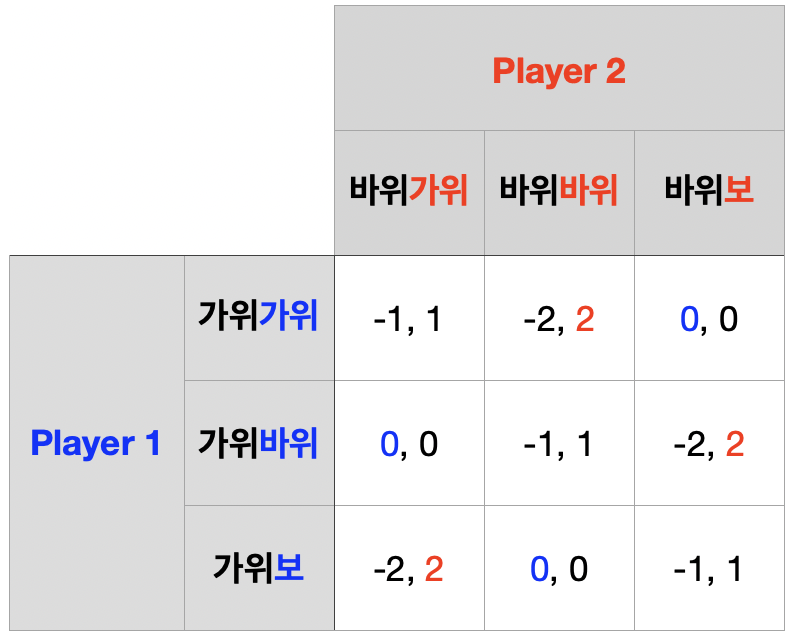
가위-바위-보 게임의 \(T\)회 반복
\((T-1)\)기까지의 정보 $\rightarrow$ \(T\)기의 역사 \(h^{T}\) \(\rightarrow\) 보수 \((R_{1},~R_{2})\)
\(T\)기 단계 게임의 내쉬균형은 순수혼합전략 내쉬균형
하위게임완전균형을 적용하면 모든 기의 순수혼합전략 내쉬균형
유한반복게임
핵심만 쏙쏙!
다음 문제에 답을 할 수 있다.
현실 세계 전략적 상황 \(\rightarrow\) 반복적 상호작용 $$\rightarrow$ 유한번$ 반복게임
합리적 경기자들은 어떤 전략을 선택하는가?
다음 문제를 생각하자.
죄인의 딜레마를 반복하자.
반복 게임의 균형으로서, 죄인의 딜레마 내쉬균형은 무엇인가?
반복게임의 하위게임 완전균형은 무엇인가?
유한번 \(T\)회 반복 죄인의 딜레마 균형은 무엇인가?
유한번 반복하는 Cournot 균형은 무엇인가?
반복게임
내쉬균형
하위게임 완전균형
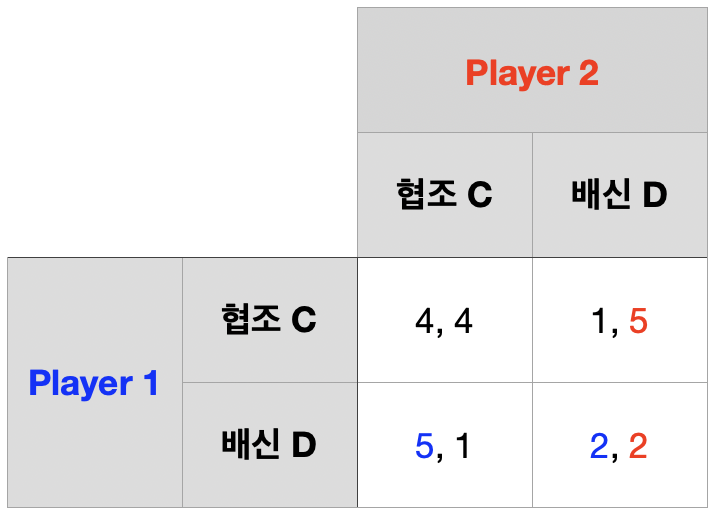
죄인의 딜레마
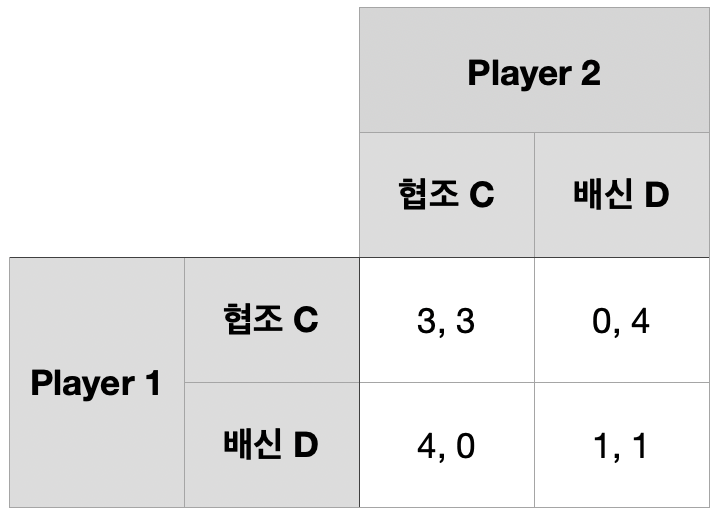
죄인의 딜레마
1회 게임(one-shot game) 내쉬균형 \(\rightarrow\) \((D,~D)\)
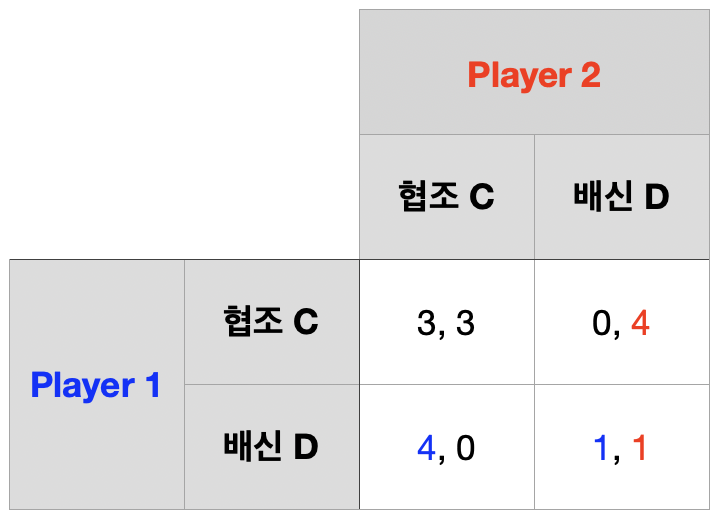
죄인의 딜레마 2회 반복
1기 단계 게임의 결과, 즉 2기의 역사 \(h^{2}\)가 \((C,~D)\)라고 하자.
2기 단계 게임 내쉬균형 \(\rightarrow\) \((D,~D)\)
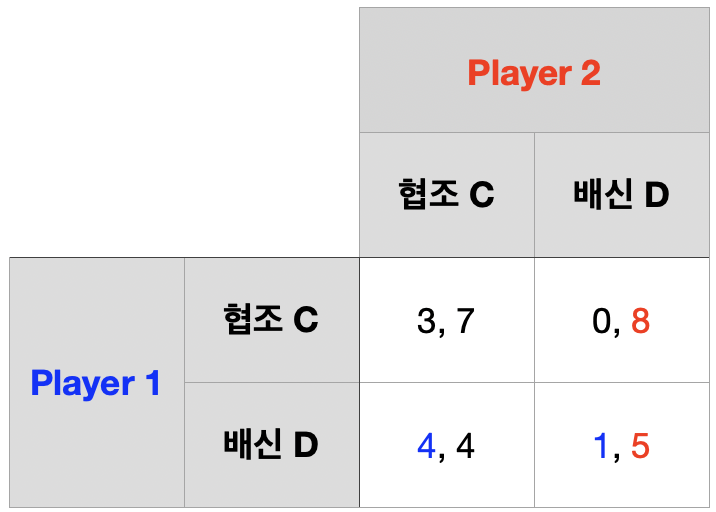
1기 단계 게임의 결과, 즉 2기의 역사 \(h^{2}\)가 \((D,~C)\)라고 하자.
2기 단계 게임 내쉬균형 \(\rightarrow\) \((D,~D)\)
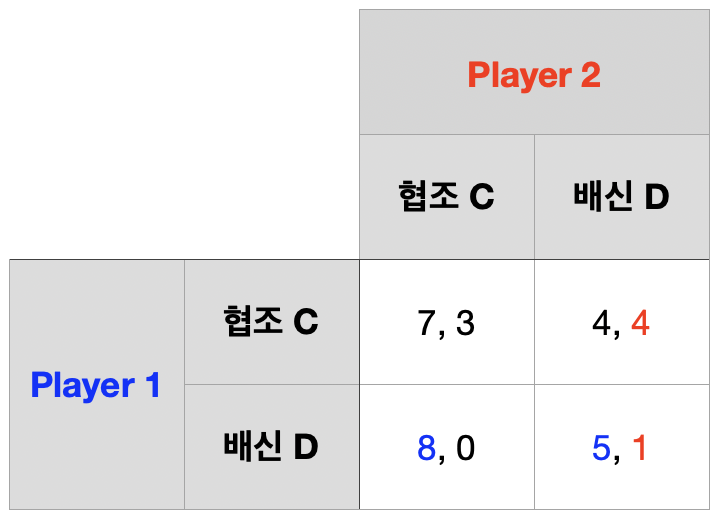
1기 단계 게임의 결과, 즉 2기의 역사 \(h^{2}\)를 모두 고려하자.
2기 단계 게임 내쉬균형 \((D,~D)\)
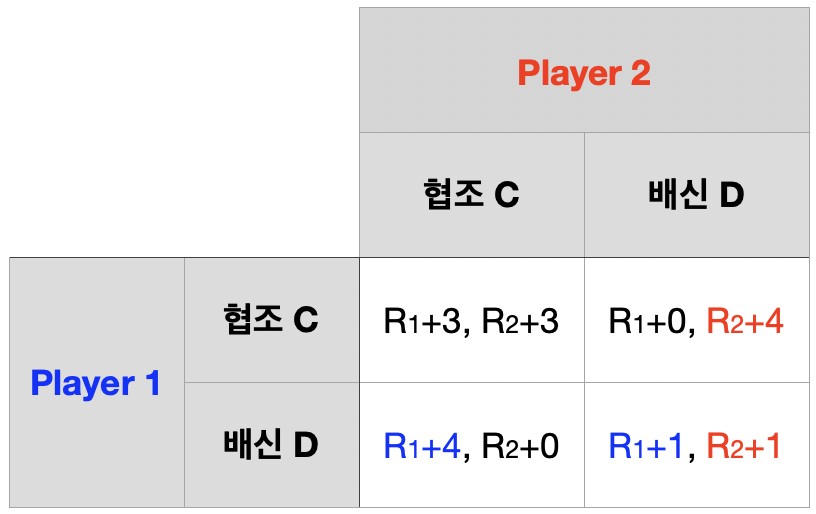
1기 단계 게임과 2기 단계 게임의 내쉬균형은 모두 \((D,~D)\)
2기 단계 게임의 균형을 역진귀납으로 1기 단계 게임에 적용하자.
하위게임 완전균형을 구하자. \(\rightarrow\) \(\{(D,~D),~(D,~D)\}\)
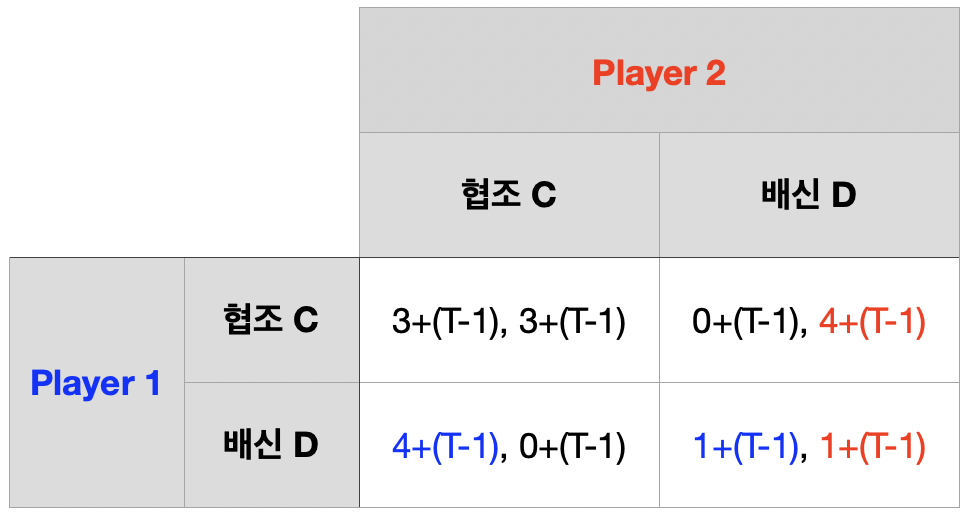
죄인의 딜레마 \(T\)회 반복
1기, 2기,\(\cdots\), \(T\)기 단계 게임의 내쉬균형은 모두 \((D,~D)\)
역진귀납을 이용한 하위게임 완전균형 \(\rightarrow\) \(\{(D,~D),~(D,~D),\cdots,~(D,~D)\}\)
응용해 봅시다.
Cournot 모형
시장(역)수요함수 \(P=12-Q\)
기업 1의 생산량 \(Q_{1}\), 기업 2의 생산량 \(Q_{2}\)
각 기업은 동질의 재화를 공급
각 기업의 고정비용과 가변비용은 모두 0
각 기업의 이윤 구조
각 기업의 이윤극대화 조건
- 1계조건과 2계조건
시장균형가격 \(\rightarrow\) \(P=4\)
각 기업의 이윤 \(\rightarrow\) \(\pi_{i}=16\)
\(T\)회 반복 Cournot 모형
모든 기의 내쉬균형 \(\rightarrow\) \((Q_{1},~Q_{2})=(4,~4)\)
하위게임 완전균형 \(\rightarrow\) \(\{(4,~4),~(4,~4),\cdots,~(4,~4)\}\)
무한반복게임
핵심만 쏙쏙!
다음 문제에 답을 할 수 있다.
현실 세계 전략적 상황 \(\rightarrow\) 반복적 상호작용 \(\rightarrow\) 무한번 반복게임
합리적 경기자들은 어떤 전략을 선택하는가?
다음 문제를 생각하자.
지금 당장이 중요한가? 아니면 미래가 중요한가?
죄인의 딜레마를 무한 반복하면 유한 반복과 차이가 있는가?
무한 반복하는 Cournot 균형은 무엇인가?
반복게임에서의 보수
100을 이자율 10%로 저축하면 1기 후 \(\rightarrow\) \((1+0.1)\times 100=100+10\)
1기 후 110의 현재가치 \(\dfrac{110}{1+0.1}=100\)
1기 후의 보수 \(R\)의 현재가치 \(\rightarrow\) \(\dfrac{R}{1+r}\)
1기 후의 보수 \(R\)을 현재가치화하는 할인인자 \(0<\delta<1\) \(\rightarrow\) \(\delta R\)
반복게임
각 기의 보수 \(R_{1},~R_{2},\cdots,~R_{T}\) \(\rightarrow\) 보수의 현재가치 합 \(V\)
\[\begin{split} V&=R_{1}+\frac{R_{2}}{1+r}+\frac{R_{3}}{(1+r)^{2}}+\cdots+\frac{R_{T}}{(1+r)^{T-1}}\\ &=R_{1}+\delta R_{2}+\delta^{2} R_{3}+\cdots+\delta^{T-1} R_{T}\\ &=\sum_{t=1}^{T}\delta^{t-1} R_{t} \end{split}\]반복게임 보수의 현재가치 합
- 등비수열의 합 (단, 공비 \(r\ne1\))
- 보수의 현재가치 합 \(V\)
- 한반복게임의 평균할인보수 \(v\)
- 무한반복게임의 평균할인보수 \(v\)
무한반복게임의 평균할인보수 \(v\)
- 무한반복게임의 평균할인보수 \(v\)는 \(R_{1}\)과 \(v(R_{2},~R_{3},\cdots)\)의 가중평균
1기의 보수 \(R_{1}\)
2기부터 시작되는 평균할인보수 \(v(R_{2},~R_{3},\cdots)\)
할인인자 \(\delta\)
경기자의 인내력 또는 미래지향적 성향을 의미
할인인자 \(\delta\)가 클수록 지금보다는 미래의 보수에 가중치
- \(\rightarrow\) \(\delta\to1\)이면 현재의 보수에 0의 가중치
할인인자 \(\delta\)가 작을수록 미래보다는 현재의 보수에 가중치
- \(\rightarrow\) \(\delta\to0\)이면 현재의 보수, 즉 눈앞의 이익을 중시
죄인의 딜레마
신사전략(nice)
- 과거 역사가 무엇이건 또는 상대방이 어떤 선택을 했건 무조건 \(C\)를 반복
깡패전략(nasty)
- 과거 역사가 무엇이건 또는 상대방이 어떤 선택을 했건 무조건 \(D\)를 반복
무자비전략(grim)
- 상대방이 지난 기에 \(D\)를 선택했다면 자신은 이번 기부터 무조건 \(D\)를 선택
무한반복 죄수의 딜레마 내쉬균형
상대방의 반복게임 전략을 주어진 것으로 가정할 때 자신의 전략을 바꿀 유인이 없다.
자신의 반복게임 전략을 주어진 것으로 가정할 때 상대방의 전략을 바꿀 유인이 없다.
신사전략(nice)
경기자 2의 신사전략을 가정
경기자 1이 신사전략을 고수
- 경기자 1이 깡패전략으로 변경
- 신사전략에서 깡패전략으로 바꿀 유인이 있기에 (신사전략, 신사전략)은 내쉬균형이 아니다.
깡패전략(nasty)
경기자 2의 깡패전략을 가정
경기자 1이 깡패전략을 고수
- 경기자 1이 신사전략으로 변경
- 깡패전략에서 신사전략으로 바꿀 유인이 없기에 (깡패전략, 깡패전략)은 내쉬균형이다.
무자비전략(grim)
경기자 2의 무자비전략을 가정
경기자 2는 1기에 \(C\)를 선택하고 있다고 가정
경기자 1이 \(C\)를 선택
- 경기자 1이 \(D\)를 선택
- 모든 경기자 \(v_{C}\ge v_{D}~\rightarrow~\delta\ge \dfrac{1}{3}\)일 때, (무자비전략, 무자비전략)은 내쉬균형이다.
정리하기
일회게임 G가 유일한 내쉬균형을 갖는다면, 게임 G의 \(T\)회 유한반복게임에는 유일한 하위게임완전균형이 존재한다. 즉, 모든 기에 일회게임 G의 내쉬균형이 단순 되풀이된다.
무한반복게임은 신사전략, 깡패전략, 무자비전략 등 반복게임 전략이 있으며, 할인인자에 따라 무자비전략은 내쉬균형이 될 수 있다.